How Does Named Entity Recognition (NER) Work?
Recognizing named entities in texts
Named entity recognition (NER) identifies features of interest - such as names of people, places and organizations, in addition to dates, currency and other special categories of nouns - within language data (e.g. unstructured text).
The best way to grasp NER is to try it out! Visit the CoreNLP demo and paste a short passage of text containing at least some proper names into the “– Text to annotate –” field (the maximum number of characters in the online demo is 5000).
Remove the “parts-of-speech” and “dependency parse” options from the “– Annotations –” field to limit our results to named entities and submit the text for analysis.
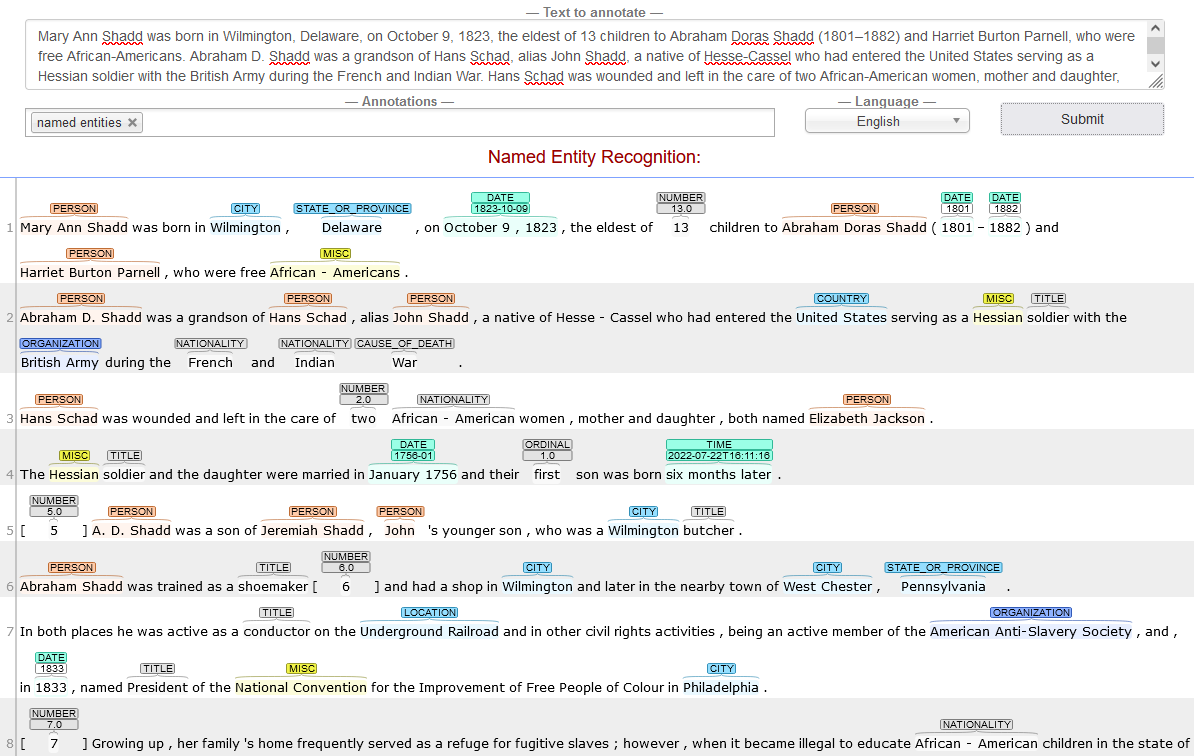
In the screenshot above, CoreNLP has annotated the text from a Wikipedia article on the American-Canadian anti-slavery activist Mary Ann Shadd, tagging words (tokens) with labels like “Person,” “Country,” “Organization,” and “Date.”
Although we can appreciate the utility of CoreNLP annotations in analyzing texts, the 5000 character maximum of the web-based version makes it impractical to scale up for larger corpora. You can download the full version of CoreNLP to experiment with but we will be using a different NLP tool, SpaCy, for the lesson.
A quick introduction to the NLP workflow (pipeline)
How does an NLP tool like CoreNLP or SpaCy go about identifying named entities within an unstructured text corpus?
If you have ever gone through the intellectual exercise of considering how to tell a computer to do a simple task (for humans) - like make toast - you quickly discover that much of what is implicit in our own cognitive processes (“verify toaster is plugged in”) must be articulated in a programmatic manner. NER is no different, requiring a number of preparatory steps before it can be performed.
Tokenization
Most computational text analysis methods, including NER, first involve tokenizing the data - or segmenting the text into tokens - so that each word can be examined individually. If you completed the “Pre-processing Digitized Texts” workshop, you tokenized a text document in OpenRefine to make it possible to correct multiple errors with one operation. When performing computational text analysis, tokenization is done by the natural language processing system.
Once we are able to approach texts at the level of the word, we can then perform other pre-processing tasks in the text analysis workflow such as those described below.
Stop word removal
Commonly used words - like the, of and its in the English language - are typically filtered out from the corpus for the sake of efficiency because they are not likely to be of interest. With many NLP tools, it is possible to either add stop words that you may wish to ignore in your analysis or omit existing stop words from the list which are, in fact, relevant to your analysis.
Part of speech (PoS or POS) tagging
PoS tagging is a form of annotation that evaluates each word to determine its correspondence to grammatical parts of speech such as nouns, pronouns, verbs, adverbs, adjectives and so on. Unlike the previous two tasks, which can be explicitly programmed with formal rules - like “create a new token each time a whitespace character is encountered” - PoS tagging and the other tasks that follow rely instead on machine learning to make generalized predictions about what tag is most appropriate. For example, whether “saw” is a verb or a noun given its context.
NLP tools use trained language models to make their predictions, which are “taught” through many examples of the various categories being modelled. Often - and in the current lesson - you will be working with a model trained by someone else, like the developers of the tool. It is usually possible - if time-consuming - to train your own model if the tool’s supplied model is inadequate for your purposes.
Stemming or lemmatization
A word can be expressed in different forms; for example, pluralized nouns (“pickle”, “pickles”) or conjugated verbs (“pickling”, “pickle”, “pickled”). Although we humans recognize that they are semantically related, a computer must be instructed to regard them as such. For the purposes of being able to compare like with like, many NLP workflows involve reducing words to their root form, or lemma.
There are two approaches to the task of determining the lemma of a word in NLP:
- stemming, a faster but more error-prone technique that works by chopping off the end of a word in the hopes that it will achieve the intended goal most of the time, and
- lemmatization, which uses a vocabulary and performs morphological analysis to more accurately identify the lemma.
Trade-offs: Speed Vs. Accuracy
As we get more familiar with the NLP workflow, we will encounter various concessions that developers make in designing their tools to increase the speed or maximize the efficiency of processes. For example, with respect to tokenization: we know that a space does not necessarily indicate the beginning of a new word but creating a comprehensive list of exceptions in various languages would be very time-consuming. Indeed, in the “Pre-Processing Digitized Texts” lesson, we discussed setting the bar for accuracy relatively low because it would take too long to correct every error.
Accuracy is not the only feature traded off for speed or efficiency in the design of computer programs and algorithms. The Python library we will be using for the lesson, SpaCy, limits the choices we have in how to approach the NLP workflow by making decisions for us in order to optimize for speed. Most troubling is the privileging of efficiency over equity - whether it is done consciously or unconsciously - by not involving minoritized groups in the design process, by assuming that the user shares the dominant subject position of the developer, by not taking the time to assemble fully representative training datasets and so on.
Dependency parsing
Examining individual tokens in isolation can obscure the contextual information from surrounding words that would be critical to their meaning. Dependency parsing infers syntactic relationships between tokens, which can then help other components of the NLP workflow; for example, tokenization would undermine the semantic connection between “New” and “York.” In addition to merging tokens that have been over-segmented, dependency parsing annotates the language data with lexical information in a tree-like structure.
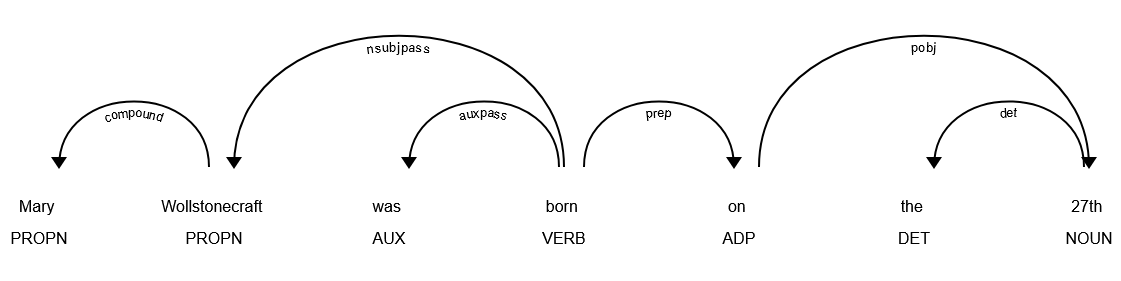
The above screenshot shows the first sentence of the introduction in the “wollstonecraft.txt” document visualized with SpaCy’s dependency parsing visualizer. The curved line that connects the tokens “Mary” and “Wollstonecraft” and annotated with the “compound” label indicates that SpaCy has re-associated the two tokens which comprise a proper name. The dependency parsing visualizer has also identified relationships like prepositional modifiers (“prep”) and the objects of preposition (“pobj”), sometimes nesting the labelled connecting lines to express more complex dependencies. A discussion of the grammatical rules that the dependency parser uses is outside of the scope of the workshop but you can refer to the full list of the labels for more information.
Some of the tasks above may depend on others, meaning that the order of operations matters. The lemmatization component of a workflow is aided by knowing whether “saw” is a verb or a noun from the PoS tagging task. Likewise, PoS tagging - which identifies proper nouns - can help the NER step focus on a subset of tokens. At the same time, dependency parsing happens after NER in the CoreNLP pipeline while SpaCy performs dependency parsing before NER.
Not all tasks may be performed in a given NLP workflow or in the same order, and NLP systems can use different rules to perform them. The same analytical technique may therefore not return the same results across several NLP tools. As part of your analysis, consider comparing the tagged entities produced by multiple tools (e.g. SpaCy, NLTK and CoreNLP) with a small sample from your corpus. Although it will take a bit of time to get familiar with each tool, you can avoid the deflating experience of finding out that there may have been a better tool for your task after processing gigabytes of language data!
Classifying named entities
Imagine writing a rule-based program that provides specific instructions on how to identify named entities. With English language data, you might tell it to look for tokens beginning with a capital letter. As a broad strategy, the program would probably work most of the time - but also return a lot of false positives, since sentences start with a capital letter in English.
You could further refine the instructions to ignore tokens that follow a period, but there would be cases where sentences start with named entities - not to mention, proper names that contain an initial! Moreover, what about names like “danah boyd”?
The difficulties in explicitly articulating rules for identifying named entities quickly become apparent. Many NER tools instead rely on machine learning to make predictions regarding whether or not a term is a named entity.
Supervised machine learning systems are trained with a dataset that has been annotated by humans; in the case of NER, the annotations would reflect the entity type labels that the trained pipleline uses (e.g. “PERSON”, “ORG”, “GPE” etc.). Training the machine learning system allows it to create a statistical model - that is, a generalized theory - to inform predictions when encountering novel, unannotated datasets.
Needless to say, the composition of the training dataset has a tremendous influence on what entities the NER tool is able to recognize. We will return to the relationship between training data and bias in “Behind the Interface.”